
Your Spam Filter Walked So GPT Could Run | Copy My Notes: AI Engineering [Chapter 1]
Notes on AI Engineering, Chapter 1: AI isn't new, but it did have a makeover. You don't need to abandon your current skills to become an AI engineer; you just have to adapt them!


Be honest…those technical books you bought (with great intentions) are just sitting on your bookshelf collecting dust, aren’t they? It’s not just you. We’ve all been there! Every time I buy a technical book, I claim it’s going to be my gateway to becoming more technical, but I struggle to stay engaged after the first few chapters. I’ve finally decided to put an end to that in 2026!
Welcome to Cozy Coding Book Club, where I’m diving into a series of technical books to expand my learning. The best part? I’m bringing you with me. If you’re also reading the book, let’s have a conversation about the reading in the comments! Not sure if you’re ready to dive in? Consider this your Spark Notes guide to each chapter. Each post will include my raw notes, thoughts, questions, and additional resources I found useful.
The first book in the Cozy Coding Book Club series is AI Engineering by Chip Huyen. This, admittedly, is a reread for me, but still extremely relevant today! AI is reshaping our day-to-day lives faster than I ever could have imagined. That change has a way of breeding fear and anxiety about the unknown and the things we don’t understand. My first technical read of 2026 is a practical guide to building applications with large foundation models, focusing on the engineering disciplines required for reliability, scale, and safety. I’m looking forward to ending this read with a direct path on what’s required to be an AI engineer in 2026 and principles I can use now to build AI applications.
I’m so excited to embark on this journey together!
Chapter 1: Introduction to Building AI Applications with Foundation Models
Chapter 1 serves two massive purposes: it officially defines AI Engineering as its own discipline, and it hands us the blueprint for building apps on top of Foundation Models. Personally, the part that fascinated me wasn’t the architecture. It was the breakdown of how these models actually work.
Chip walks us through the mechanics of language models, and it completely shattered my mental image of “Chatting with AI.” We tend to think of ChatGPT or Claude as conversational partners, but the book clarifies that they are actually just completion machines. They aren’t actually thinking. They are calculating statistical probabilities of which word is most likely to appear next in a specific context.
From there, the chapter breaks down foundation models and how they differ from the single-task models of the past. But the bulk of the chapter forces us to take a critical look at planning. Before we rush to add AI to everything, we have to ask: “Do we actually need this?” I know it’s controversial to say in 2026, but sometimes the answer is no, you don’t need AI. Chip emphasizes that if an app works perfectly fine without AI, adding it might just introduce unnecessary risk and cost.
Finally, we get to the part that will give front-end and full-stack engineers like me hope: The New AI Stack. I don’t know about you, but I’ve always assumed AI and ML were for data scientists and math geniuses. Chip explicitly states that AI Engineering has an “increased emphasis on application development,” bringing it much closer to full-stack development. This gives us a bridge to upskilling that doesn’t require us to abandon the skills we’ve worked so hard to build. We just need to extend them. We’re halfway there!
One of my biggest takeaways (and validations) from this chapter: AI is evolving quickly today, but it’s not new. We’ve been using machine learning algorithms for decades. You’ve likely interacted with old AI every single day without realizing it. Think about that spam filter in your email that quietly decides what makes it to your inbox.
Those were single-task. A spam filter could catch a phishing scam, but it couldn’t write a poem or debug your React component. It was trained for one specific job. What Chip explains is that we have now entered the era of foundation models, models trained on such broad data that they mark “the end of single-task models”. It feels like this technology appeared out of thin air, but really, it has moved from being specialists to generalists that we can adapt for anything. The history is long, but the access is what’s new.
The Study Session: My Raw Notes
1. Language Models
What’s a language model?
You can think of a language model as a completion machine: given a text (prompt), it tries to complete that text. Completions are predictions based on probabilities and not guaranteed to be correct. Completion is not the same thing as engaging in conversation.
A language model encodes statistical information about one or more languages. Intuitively, this information tells us how likely a word is to appear in a given context.
Example: “My favorite color is _____” a language model that encodes English should predict purple more than car
The basic unit of a language model is token - a character, word, or part of a work (like -tion) depending on the model. The process of breaking the original text into tokens is called tokenization. The set of all tokens a model can work with is the model’s vocabulary.

An example of the tokens that comprise the sentence “Hey, my name is Bree!” from platform.openai.com/tokenizer Why do language models use token as their unit of measure instead of words or character?
Tokens allow models to break words up into meaningful components. Like “cooking” can become “cook” and “ing” (and verb and tense)
There are fewer unique tokens than unique words, reducing the models vocabulary size and making it more efficient
Tokens help a model process unknown words
There are two main types of language models:
Masked Language Models which are trained to predict missing tokens anywhere in a sequence using the context from both before and after the missing tokens (trained to fill in the blank). Commonly used for non-generative tasks like sentiment analysis and text classification. Also useful for tasks requiring an understanding of overall context (like debugging) where a model needs to understand both the preceding and following code to identify errors.
Autoregressive Language Models which are trained to predict the next token in a sequence using only the preceding tokens. Used for tasks like text generation.

Language models can be trained using self-supervision while many other models require supervision. Supervision refers to the training process of ML algorithms using labeled data (which can be expensive and slow to obtain).
Supervision: you label examples to show the behaviors you want the model to learn and then train the model on those examples. Once trained, the model can be applied to new data. It’s expensive and time consuming.
Self-supervision: the model can infer labels from input data. Language modeling is self-supervised because each input sequence provides both the labels (tokens to be predicted) and the context the model can use to predict the labels.
How large does a model have to be to be considered large? A model’s size is typically measured by its number of parameters (a variable within an ML model that is updated throughout the training process). The more parameters the model had, the greater its capacity to learn desired behaviors.
What’s a foundation model and why are the beneficial?
A large-scale AI neural networks, such as LLMs or vision models, trained on vast, unlabeled data using self-supervised learning. They mark the end of single task models (like using one model for a single task). We can now use one model with multiple techniques to generate the desired output. These include:
Prompt engineering: crafting detailed instructions with examples of desired results
Retrieval-augmented generation (RAG): Using a database to supplement instructions
Finetuning: Further training a model based on a dataset of high quality desired outputs
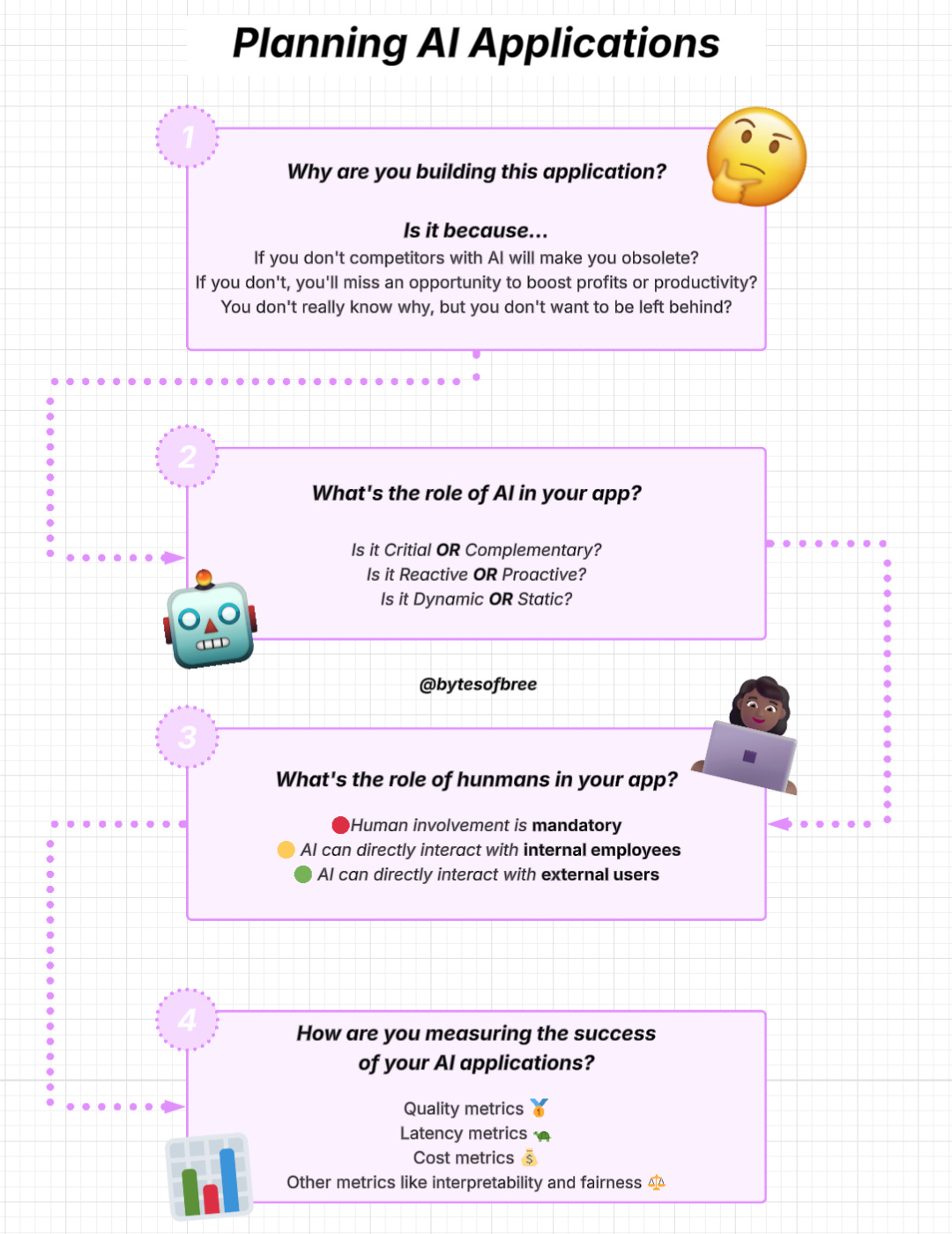
2. Planning AI Applications
Use case evaluation. Why are you building this application? It’s usually a response to different risks and opportunities:
If you don’t, competitors with AI will make you obsolete. If AI poses a major threat to your business, incorporating AI must have the high-priority.
If you don’t do this, you’ll miss opportunities to boost profits and productivity. Embracing AI for the opportunity it brings
You’re unsure where AI will fit into your business, but you don’t want to be left behind.
What’s the role of AI and humans in the app?
What role will AI play?
Critical or complementary: It an app can still work without AI, AI is complementary (for example: FaceID won’t work with AI but Gmail will still work without Smart compose). The more critical AI is to the app, the more accurate and reliable it has to be.
Reactive or proactive: A retroactive feature shows its responded in reaction to a users’ request or specific actions. Proactive features show its response when there’s an opportunity for it. For example: chatbot is reactive, traffic alerts on Google maps are proactive).
Dynamic or static: Dynamic features are updated continually with user feedback. Static features are updated periodically. For example: FaceID needs to be updated as peoples faces change over time but object detection in Google Photos only needs to be updated when Google photos is upgraded.
What role will humans play?
Microsofts proposed framework for increasing AI automation in products with crawl-walk-run:
Crawl: human involvement is mandatory
Walk: AI can directly interact with internal employees
Run: Increased automation, potentially including direct AI interactions with external users
How will you measure success of your AI application? It’s the most important metric for your business. To ensure a product isn’t put in front of customers before it’s ready, have clear expectations on its usefulness threshold: how good it has to be to be useful.
Quality metrics to measure the quality of responses
Latency metrics like TTFT (time to first token), TPOT (time per output token), and total latency
Cost metrics: How much it costs per inference request
Other metrics like interpretability and fairness
You need to set measurable goals to achieve your metrics. A good initial demo doesn’t promise a good end product. “The journey from 0 to 60 was easy, whereas progressing from 60 to 100 becomes exceedingly challenging.”
You need to think about how this product might change over time and how it should be maintained. Maintenance of an AI product has the added challenge of AI’s fast pace of change.
Good things:
Context length getting longer
Output getting better
Model inference, the process of computing an output given an input, getting faster
Bad / harder to adapt to things:
Friction in workflows
Changing costs
Government regulations
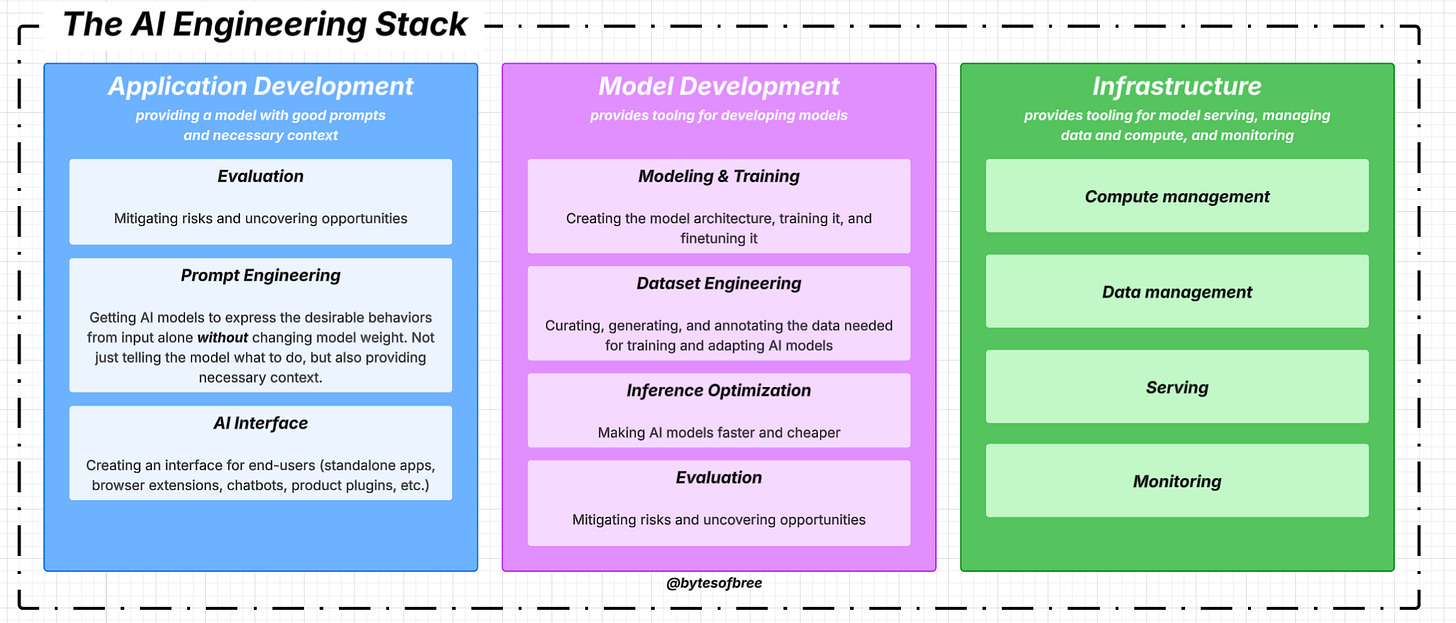
3. The AI Engineering Stack
What’s AI Engineering?
AI engineering has evolved out of ML engineering. Some companies are treating these roles the same, while others are treating them as different professions. Either way, they have significant overlap.
There are three layers to any AI application stack:
Application development: involves providing a model with good prompts and necessary context. Requires rigorous evaluation and good interfaces.
Model development: provides tooling for developing models including frameworks for modeling, training, finetuning, and inference optimization. This layer also contains dataset engineering. Requires rigorous evaluation
Infrastructure: includes tooling for model serving, managing data and compute, and monitoring
AI Engineering vs. ML Engineering: Building applications using foundation models today differs from traditional ML engineering in three ways:
Without foundation models, you have to train your own models for your applications. AI engineering - you use a model someone has trained for you (meaning less focus on modeling and training and more on model adaptation)
AI Engineering works on models that are bigger, consume more computer resources, and incur higher latency than traditional ML engineering (meaning more pressure for efficient training and inference optimization)
AI engineering works with models that can produce open ended outputs (which give models the flexibility to be used for more tasks, but are harder to evaluate)
TL;DR - AI engineering is less about model development and more about adapting and evaluating models
Model Adaptation techniques (two categories based on whether they require updating the model weights)
prompt based techniques (that require prompt engineering) adapt a model without updating model weights. You adapt it by giving it instructions and context instead of changing the model itself. Easier to get started and requires less data. Allows you to experiment with more models, but not enough for complex tasks
finetuning requires updating model weights (changes to the model itself). More complicated, requires more data, but can improve model quality, latency and cost.
Model development is the layer most commonly associated with traditional ML engineering and it has three main responsibilities:
Modeling and training: coming up with a model architecture, training it, and finetuning it. Example tools: TensorFlow, Hugging Face Transformers, Meta’s PyTorch. Requires ML knowledge and knowing different types of ML algorithms and how a model learns. Foundation models make it so that ML knowledge is no longer a must have for building AI applications
Pre-training: training a model from scratch— the model weights are randomly initialized
Finetuning: continuing to train a previously trained model — the model weights are obtained from previous training process
Post-training: training a model after the pre-training phase (it’s usually called post-training when done by model developers)
Dataset engineering: curating, generating, and annotating the data needed for training and adapting AI models. Traditional ML engineering most use cases are close-ended (a model’s output can only be among predefined values — ex: spam classification can either be spam or not spam and that’s it). Foundation models are open-ended queries. Traditional ML works with more tabular data, foundation models is unstructured data.
Inference optimization: making models faster and cheaper
The application development layer consists of three responsibilities:
Evaluation: all about mitigating risks and uncovering opportunities. Needed to select models, benchmark progress, determine if an application is ready for development, and detect opportunities and issues
Prompt engineering: getting AI models to express the desirable behaviors from the input alone without changing the model weights. Not just telling the model what to do, but also giving it the necessary context and tools to go a given task.
AI interface: creating an interface for end users to interact with you AI applications (standalone apps, browser extensions, chatbots, product plugins)
AI engineering has increased emphasis on application development (especially on interfaces) and bring it closer to full stack development. The rising importance of interfaces leads to a shift in the design of AI toolings to attract more frontend engineers. ML eng is usually python centric. With foundation models, python is still popular, but there’s increasing support for JavaScript APIs
With tradition ML, you start with gathering data and training a model and building the product is last. With AI eng, you start building the product first and only invest in the models once the product shows promise.
Final Thoughts on Chapter 1
If you take one thing away from Chapter 1, let it be this: You are not behind. The entire industry is resetting right now, and by simply reading this, you are already ahead of the curve. Don’t let the technical jargon or the “math anxiety” talk you out of your bag. We are learning this to become the architects of our own careers…and the first step is complete!
I’ll see you next week for Chapter 2: Understanding Foundation Models!
I want to hear from you!
After reading about the differences between ML engineer and AI engineer, which lane do you gravitate to? Are you a Builder (AI Engineer / Product focus) or a Trainer (ML Engineer / Research focus)? Let me know in the comments!